
Эволюция поисковых систем предъявляет новые требования к написанию текстов для сайта. SEO-копирайтинг уходит в прошлое, на смену приходит LSI-копирайтинг. Подробно рассказываем, что это и как работает.
Задача поисковых систем — найти информацию, которая наиболее точно отвечает запросам пользователя. Для этого машины должны были научиться распознавать смысл на основе содержания, а не только по отдельным «маякам» — поисковым запросам.
Классическая схема «запрос-документ» стала неактуальной из-за заспамленности большинства тематик. Поэтому ей на смену пришли алгоритмы латентного семантического анализа, а затем нейросети. В ответ специалисты SEO стали внедрять LSI-копирайтинг.
Термин
LSI-копирайтинг — метод написания текстов на основе анализа синонимов поискового запроса и сопутствующих ключевых слов.
Цель — повышение релевантности, полезности, актуальности и достоверности материала. LSI-копирайтинг помогает поисковым системам лучше понимать смысл и содержание текста. В результате сайт может попасть на первые страницы выдачи, даже имея минимальное количество ключевых слов.
На практике это значит, что в тексте необходимо использовать синонимы основного запроса, сопутствующие ключевые слова и дополнительные фразы из смежных тематик. Это позволит полностью охватить и раскрыть тему. Такой контент оценят и пользователи, и поисковые системы.
История
В 1988 latent semantic analysis (LSA) получил патент U.S. Patent 4,839,853. Создатели метода — группа инженеров-исследователей: Скотт Дирвестер, Сьюзен Дюмэ, Джордж Фурнаш, Ричард Харшман, Томас Ландауэр, Карен Lochbaum и Линн Стритер.
Первоначально LSA применяли для выявления семантической структуры и автоматического индексирования текста. Затем — для построения когнитивных моделей и представления баз знаний. В США метод использовался для проверки качества обучающих методик и знаний школьников.
Суть метода
LSA, латентный семантический анализ — способ обработки информации на естественном языке. Он анализирует связь между коллекциями документов и терминами, которые в них встречаются. Латентный семантический анализ сопоставляет запросы и документы согласно тематике. Это позволяет выявлять скрытые ассоциативные и семантические связи.
LSI — аббревиатура от latent semantic indexing, с английского — латентное семантическое индексирование. Это способ использования LSA в области поиска информации.
Проще говоря, LSA позволяет машинам понимать смысл и содержание документа. А при ранжировании уравнивает «веса» разных по написанию, но близких по смыслу слов. Таким образом структурируются синонимы и запросы схожей тематики.
Основа системы — терм-документная матрица, разбор которой и является LSA. Терм-документная матрица представляет собой таблицу, в которой совмещаются «термы» (слова, фразы, термины) и документы. Строки соответствуют документам, а столбцы — терминам. Число обозначает количество пересечений.
Процесс семантического анализа подобен работе простейшей нейросети — машина ищет пересечения связи между двумя слоями данных. Матрица описывает частоту, с которой встречаются термины в коллекциях документов.
{ads}
LSI в алгоритмах поисковых систем
Первое упоминание LSA в поисковых системах связано с алгоритмом Panda от Google. Обновление ставило себе цель — найти и снизить количество контента низкого качества, который был создан с целью манипуляции поисковой выдачей. Алгоритм был запущен в феврале 2011, а уже в 2012 году появились первые упоминания об LSI-копирайтинге.
Окончательно новые требования к качеству текстов сформировались к 2013 году. В это время Google запустил новый алгоритм — Hummingbird («Колибри»). Главное отличие нового алгоритма — поиск стал понимать поисковые запросы разговорного типа. Google научился отыскивать нужные документы, исходя из семантических связей, а не просто по запросам.
«Яндекс» подхватил эстафету в ноябре 2016 года — запустил алгоритм «Палех». Его задача — распознавать низкочастотные и сложные запросы из «длинного хвоста». То есть понимать запросы в разговорном ключе. Общая масса таких запросов составляет порядка 40% от объема текста.
Для работы алгоритма были использованы нейросети и машинное обучение. Подробнее о механике и принципах работы алгоритма можно прочитать в блоге «Яндекс» на Хабрахабре. Введение в работу «Палеха» подогрело интерес к LSI-текстам в русскоязычном интернете.
Весной 2017 года «Яндекс» вводит «Баден-Баден» — новый алгоритм определения текстов, которые перенасыщены ключевыми словами. Тысячи сайтов попадают под фильтр и понижаются в выдаче, условием возврата трафика называется отказ от SEO-текстов.
Осенью 2017 «Яндекс» запускает «Королев» — алгоритм поиска на основе нейросетей. По заявлению «Яндекс», алгоритм «…сопоставляет смысл запросов и веб-страниц…». Новый алгоритм работает на нейросетях, но при этом не отменяет LSI, а усиливает сложившиеся тенденции. Теперь писать SEO-тексты нет никакого смысла — вместо топа можно получить фильтр за переоптимизацию.
Отличие LSI от SEO-копирайтинга
Для удобства используем сравнительную таблицу.
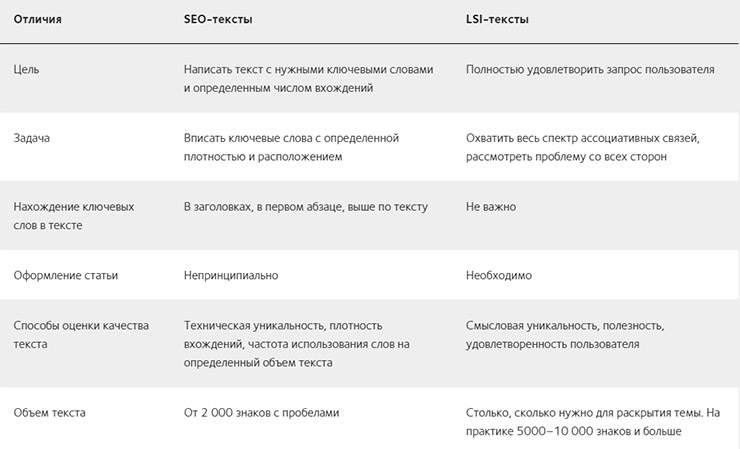
Как видим, основное отличие — отход от чисто технических параметров текста к здравому смыслу: пользе, удобству читаемости. Можно сказать, что это эволюция SEO-копирайтинга — материалы создаются для людей, а не для роботов.
Это результат того, что теперь поисковые машины оценивают релевантность контента по смыслу. Учитывается контекст, уместность, семантические варианты запросов и их окружение. Вкупе с поведенческими факторами это позволяет оценивать качество текста и потребности читателей.
Преимущества и недостатки
Преимущества
Те, кто сумел приспособиться к новым требованиям поисковых систем, получают определенные преимущества.
- Увеличивается семантическое ядро. Все LSI-фразы — это дополнительные, низкочастотные ключи по той же тематике.
- Увеличивается «длинный хвост» запросов и трафик. Используйте сопутствующие запросы и получите посетителей по широкому спектру редких ключевых слов.
- Улучшаются поведенческие факторы. Объемная, полезная статья захватит больше читательского внимания и времени. Даже просто на то, чтобы пробежаться по заголовкам и разобраться, понадобится время.
- Вырастет количество социальных сигналов и естественных ссылок. Полезным материалом делятся, о нем рассказывают, сохраняют у себя на страницах, чтобы использовать в будущем.
- Вырастут позиции в поиске по высокочастотным фразам. «Длинный хвост» запросов подтянет за собой конкурентные ключевые слова, в этом ему помогут поведенческие и социальные факторы.
- Сайт не попадет под фильтр. Все современные алгоритмы нацелены на отсев бесполезных текстов, заточенных под роботов. Использование принципов LSI-копирайтинга позволит избежать подобной ситуации.
- Проще структурировать сайт. Если раньше приходилось создавать несколько страниц для охвата синонимов или сопутствующих запросов, то теперь можно создать одну страницу.
LSI-копирайтинг требует серьезного вложения труда как SEO-специалиста, так и копирайтера. Но этот труд окупится сторицей. Вы получите стабильное нахождение в топе и внимание пользователей.
Недостатки
Несмотря на вышесказанное, LSI — не панацея и имеет ряд недостатков:
- Модель работает на допущении, что у слова есть всего одно значение.
- Текст рассматривается просто как набор слов, взаимосвязи и порядок игнорируются.
- Смысл текста не всегда может быть дословным, не учитывается сарказм, ирония, иносказания и т.п.
- Часть данных теряется в любом случае. Это происходит, потому что сингулярное разложение позволяет работать только с самыми значимыми данными терм-документной матрицы.
Однако даже с подобными недостатками метод LSI превосходит существовавшие прежде методы индексации. А использование нейросетей позволяет обучать поисковые машины еще быстрее и эффективнее.
Требования к LSI-текстам
К современным материалам предъявляются определенные требования.
- Польза и достоверность. Нужно раскрыть тему — текст должен давать пользователю полноценный ответ.
- Насыщенность LSI-фразами и наличие поисковых запросов. Нужно использовать ключевые слова, дополнительные слова из тематики и сопутствующие запросы.
- Простота изложения. Стиль и терминология подбираются таким образом, чтобы текст был понятен рядовому пользователю.
- Структура. Четкая структура и иерархия упрощают усвоение материала, читатель получает возможность «просканировать» документ и понять, о чем речь с первого взгляда.
- Ритм текста. Рекомендуется чередовать длинные и короткие предложения. Это создает определенную динамику, которая увлекает читателя.
- Грамотность и достоверность информации. Не должно быть фактических и грамматических ошибок. Недостоверность определит пользователь, а ошибки — поисковые системы. И те, и другие сделают вывод о низком качестве текста.
Подведем итог. Существует спрос на качественные тексты экспертного уровня. Они должны обладать дополнительной ценностью для пользователей и поисковых машин, а не только содержать в себе ключевые слова.
Как создать LSI-текст
Этапы работы:
- Собрать семантическое ядро из основных запросов.
- Подобрать LSI-фразы — сопутствующие запросы и дополнительные слова из тематики.
- Составить техзадание для копирайтера. Упор делать на качество текста, а не вхождения тех или иных слов. Плотность, тошнота, частота вхождения и прочие технические параметры текста не важны. Важнее, чтобы тема была раскрыта.
- Готовый текст используйте для создания плана страницы — решите, как лучше использовать визуальный контент.
LSI-ключи
Различают два вида ключей:
- Релевантные — слова из тематики главного ключа, которые дополняют и уточняют его. Также сюда относятся фразы слова, которые имеют прямое отношение к теме статьи. Наличие таких фраз в статье позволяет понять, насколько тема раскрыта.
- Синонимичные — синонимы основного запроса. На них делается упор при базовой оптимизации текста. Это позволяет не создавать дополнительных страниц и привлекать отраслевой трафик на одну страницу.
LSI-запросы можно использовать:
- В анкорах входящих ссылок.
- В заключении или вступлении статьи.
- В окружающем тексте обратных и входящих ссылок.
- В названиях изображения, подписях и ALT.
- В заголовках и метатегах.
Важно не переусердствовать и не забывать об основном запросе. Достаточно единственного упоминания в тексте.
Инструменты для сбора LSI-фраз
На данный момент существует достаточное количество способов подобрать LSI-фразы.
{ads}
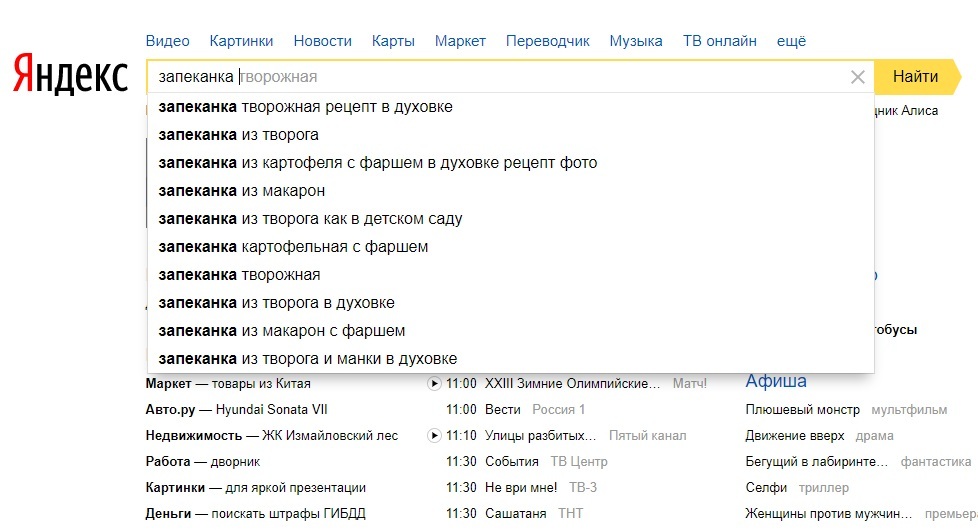
Подсказки поисковых систем
В поисковой строке «Яндекса» можно подобрать слова, если применять разные вариации написания.
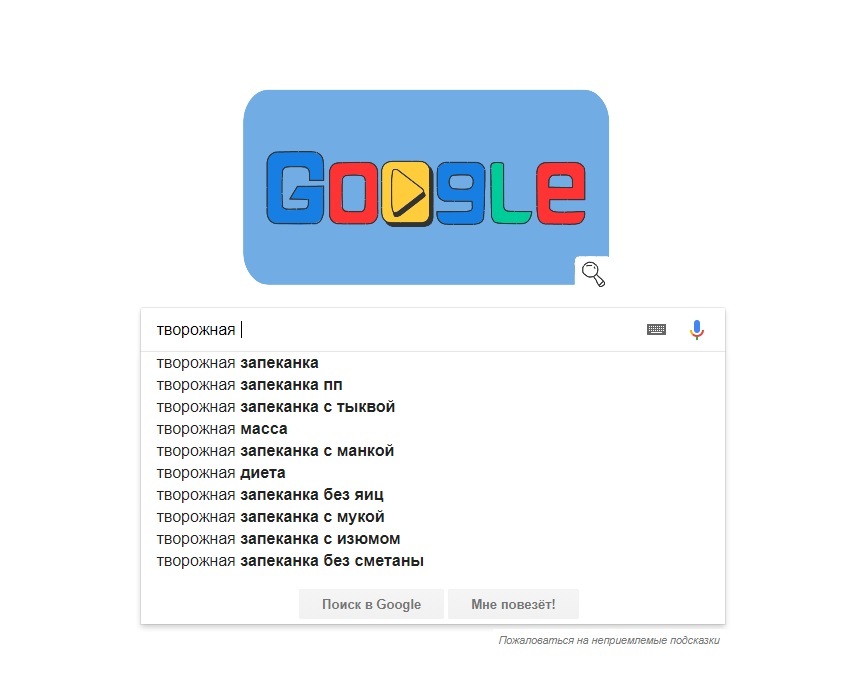
В Google ситуация схожая.
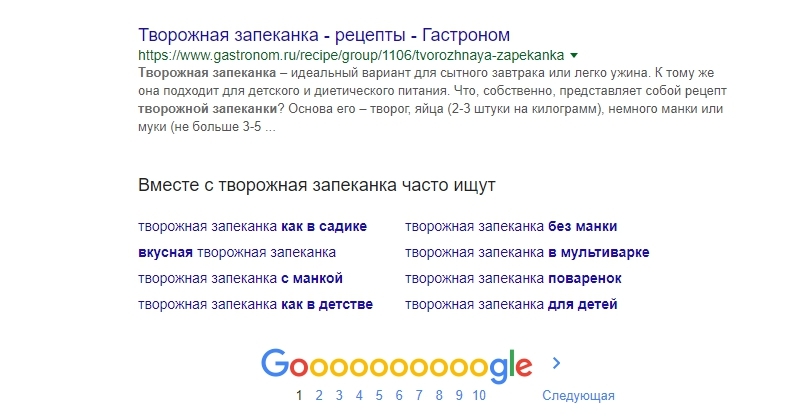
Блоки «Вместе с..» и «… часто ищут»
Статистика запросов Яндекс и Google
У обоих «поисковиков» есть собственная статистика ключевых слов. Для подбора LSI-фраз можно воспользоваться ими. Это бесплатно, но долго. В «Яндексе» — это сервис Wordstat, а в Google — Google Keyword Planner. В последнем работать можно только из аккаунта Google AdWords.
Создание структуры
Скелет любой статьи — структура. Именно она позволяет с первого взгляда оценить качество. Текст должен иметь иерархию и подчиняться внутренней логике. Части статьи не должны противоречить друг другу.
- Статья должна содержать заголовки и подзаголовки, маркированные списки и таблицы. Если это страница сайта, то стоит предусмотреть расположение отдельных элементов: кнопок, форм заказа, фотографий.
- Заголовок должен отражать основную идею материала, заголовки второго уровня — развивать тему в различных аспектах. Подзаголовки и заголовки третьего уровня указывают на частности или какие-то подробности.
- Заголовок и абзацы образуют, так называемые блоки. В каждом блоке может быть несколько абзацев. Абзац содержит от трех до шести строк и раскрывает одну определенную мысль. Короткие абзацы создают ощущение легкого, динамичного текста.
- Иерархию заголовков можно создать, опираясь на ключевые слова. Их нужно сгруппировать по смыслу. В статье идите от общего к частному — получится четкое и логичное повествование.
Обычно высокочастотные запросы касаются общей информации. Группа среднечастотников даст возможность глубже раскрыть тему. А низкочастотники позволят охватить нюансы, которые интересны пользователям.
Пример проработки структуры статьи

Постановка технического задания
Техническое задание стоит оформлять так, чтобы у копирайтера не возникало вопросов. Опишите требования максимально подробно и четко. Чем лучше вы подготовитесь, тем меньше придется переделывать. И учтите, что для LSI-копирайтинга требуются специалисты более высокого уровня. Идеально, если копирайтер имеет личный опыт в описываемой тематике.
Пример ТЗ
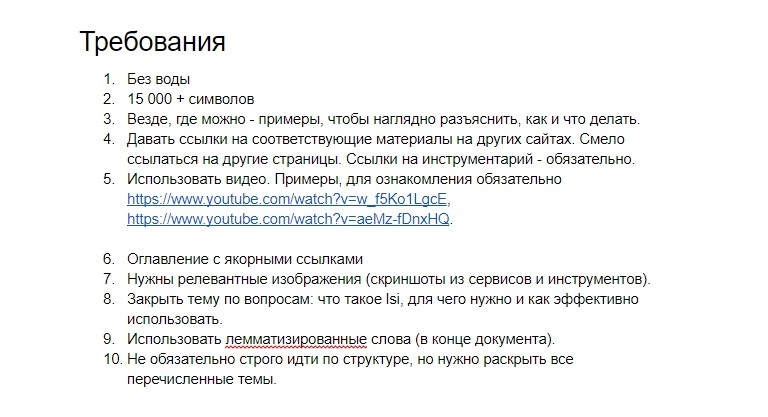
Выводы
Иногда поднимается вопрос о целесообразности подбора LSI-фраз, ведь по логике, достаточно написать текст экспертного уровня. Но здесь не все так просто — невозможно всего лишь «прикинуть» в голове весь спектр сопутствующих слов. Поисковые системы анализируют огромные базы данных, без их статистики ключевых слов вы наверняка что-нибудь упустите.
Основная задача LSI — фильтрация спама и распознавание смысла текста. Непосредственно на ранжирование она влияет опосредованно. Но в условиях жесткой конкуренции необходимо прорабатывать сайт полностью. Поскольку иногда именно мелочи могут дать решающее преимущество.
LSI-копирайтинг — не идеальный метод, но имеет ряд преимуществ: позволяет не попасть под текстовые фильтры и улучшить старые материалы. Переработка текстов дает возможность вывести сайт из-под санкций и увеличить посещаемость сайта.
Латентный семантический анализ и индексирование — явление уже свершившееся. Более того, поисковые системы уже подключили к своей работе нейросети и машинное обучение. Логическим продолжением такой эволюции будет искусственный интеллект в информационном поиске.
Источник: uplab.ru